|
||||||
| Applied
Econometrics
Econ 508 - Fall 2007 e-Tutorial 9: Unit Roots and Cointegration |
||||||
| Welcome
to the ninth issue of e-Tutorial. This issue focuses on time series models,
with special emphasis on the tests of unit roots and cointegration. I am
providing instructions for both R and STATA. I would like to remark that
the theoretical background given in class is essential to proceed with
the computational exercise below. Thus,
I recommend you to study
Prof. Koenker's Lectures 8 and 9 as you go through the tutorial.
First you need to download
the data in text format by clicking
here., or from
the Econ 508 web
site (Data).
Save it in your preferred directory (I will save my as "C:/eggs.txt".)
I suggest you to open the file in Notepad (or another text editor) and
type the name of the variable "year" in the first row, first column, before
"chic" "egg". Use <Tab> to separate the names of variables. Save the
file (I will save mine as
C:/eggs1.txt).
Inserting the Data in R: Next, you need to import
that data set to R, using the following commands:
It is useful to call the
time series package, and declare chickens and eggs as time series:
Inserting the Data in Stata: In Stata, you can type:
You will see that, because
I included variables names in the first row of the file egg1.txt, Stata
reads the first line of the data set as missing values. You should delete
this line (only!) on the Stata data editor window. Next you need to declare
your data as time series:
I. Unit Root: Augmented Dickey-Fuller Test At first, it is important that you to sketch the ADF test, explaining the NULL and the ALTERNATIVE hypotheses. ADF Test in R: I suggest you to use the R code adf.R, provided by Prof. Koenker, and available at http://www.econ.uiuc.edu/~econ472/routines.html: #Copy
from this point:
Your job is to copy the R code above and paste in the R console. This will create a R function called "adf", which runs the unit root test for each case. You should use the ADF test for each individual series (chickens and eggs), controlling for the number of lags, and the inclusion of constants and trends. Example 1: #ADF
for Chickens
Call:
Residuals:
Coefficients:
Residual
standard error: 25030 on 48 degrees of freedom
Then you can test the significance of the coefficient xD.lag(x, -1) by using the appropriate Dickey & Fuller critical values (Table B.6 from Hamilton 1994, released in class). From this starting point, you can add lags by changing L=1 to L=2 or L=3 or L=4 and so on. If wish to exclude the intercept, just substitute int=T by int=F. (As usual, T means true, i.e., inclusion, and F means false, i.e., exclusion). The same applies to the inclusion/exclusion of trend. My suggestion is that you
run 3 different types of ADF, each of them including 1, 2, 3, and 4 lags:
Example 2: #Model
with 1 lag and constant, but not trend:
Call:
Residuals:
Coefficients:
Residual
standard error: 25130 on 49 degrees of freedom
Example 3: #Model
with 1 lag, but no constant nor trend:
Call:
Residuals:
Coefficients:
Residual
standard error: 25480 on 50 degrees of freedom
Do that for each individual
series. This will generate 12 regressions for chickens, and 12 for eggs.
Very likely, some of them will indicate the presence of unit root, while
others will not. The choice of the best model can be done by calculating
AIC, SIC or any other reasonable criterion. (See comments and analogy to
OLS regressions in the respective STATA section.)
At the end, please
provide a table with the summary of your results, and draw your conclusions.
ADF Test in Stata: Once again, I recommend you to show explicitly what are the NULL and ALTERNATIVE hypotheses of this test, and the regression equations you are going to run. Then, using the STATA, you have two ways to perform the test: (1) using the command
dfuller,
or
I suggest you to consider
3 variations of the test:
A Simple Example: ADF in Stata: a) Models including constant and trend: For example, using 1 lag in the chicken series, you will have the following result dfuller chic, regress trend lags(1) Augmented Dickey-Fuller test for unit root Number of obs = 52
---------- Interpolated Dickey-Fuller ---------
------------------------------------------------------------------------------
Here the null hypothesis
is the presence of unit root. Thus, the augmented Dickey-Fuller statistic
is -1.998, and lies inside the acceptance region at 1%, 5%, and 10%. Therefore,
we cannot reject the presence of unit root.
b) Models including constant but no trend: Same rationale, but adjusting the command to: dfuller chic, regress lags(1) Augmented Dickey-Fuller test for unit root Number of obs = 52
---------- Interpolated Dickey-Fuller ---------
------------------------------------------------------------------------------
What can you conclude from
the null hypothes here?
c) Models excluding both constant and trend: Idem, but adjusting the command to: dfuller chic, noconstant regress lags(1) Augmented Dickey-Fuller test for unit root Number of obs = 52
---------- Interpolated Dickey-Fuller ---------
------------------------------------------------------------------------------
And here, what can you conclude? Those equations regard unit
root tests for the chickens annual series, using 1 lag. I recommend you
to repeat these 3 processes for lags 2,3,and 4 as well. After you complete
this cycle for chickens, you need to do the same cycle for eggs. At the
end of both cycles, you will have 24 regression outputs. If you prefer,
you don't need to report all output details, but rather concentrate on
the ADF test statistics of each equation. You can do that by ommiting the
term "regress" on the dfuller command.
Presenting your ADF results:
Comments on Unit Root Tests: P.S.1: Unit root tests are very sensitive to the number of included lags and/or constant and trends. That's the reason by which we are asking you to show all ADF statistics in the table above. Very likely, some of the results will indicate the presence of unit root while others will not. P.S.2: How to make a general conclusion on the test results with so many models available? Johnston & DiNardo (1997, p.226), for example, mention that one of the objectives of including lags is to achieve white noise residuals. Other authors recommend the use AIC or SIC in the model selection. P.S.3: It is quite simple to calculate information criteria in ADF tests. Each output of "dfuller" corresponds to a linear regression on the lags, constant, and/or trend of the series (for a time trend, you can "approximate" the regression coefficient by using a vector from 1 to 54, instead of years). From OLS regression, you recover the sample size, the RSS, and the # of parameters requested to calculate SIC or AIC, plus the original ADF statistic. But remember to use the Dickey-Fuller critical values. Example: The ADF test for unit root on the egg series, using 4 lags, but no constant nor trend is as follows: dfuller egg, noconstant regress lags(4) Augmented
Dickey-Fuller test for unit root
Number of obs = 49
Similar output can be obtained by linear regression as follows: regress D.egg L.egg LD.egg L2D.egg L3D.egg L4D.egg, noconstant
Source | SS
df MS
Number of obs = 49
Did you understand why? Note that the t-statistic
for the lag of egg (L1) is the same as the ADF statistic, but the distribution
used in the ADF hypothesis testing procedure is no longer the trivial t-student.
Because of the unit root consequences, specific critical values are provided
by Dickey and Fuller to test such statistic (Table B.6 from Hamilton 1994,
released in class).
II. Cointegration: Engle-Granger Test Here I recommend you to sketch the Engle-Granger test, explaining the NULL and the ALTERNATIVE hypotheses. : Engle-Granger in R: The test can be done in 3 steps, as follows: (i) Pre-test the variables for the presence of unit roots (done above) and check if they are integrated of the same order (ii) Regress the long run equilibrium model of chickens vs. eggs Engle<-lm(chic~egg)
Call:
Residuals:
Coefficients:
Residual
standard error: 45950 on 52 degrees of freedom
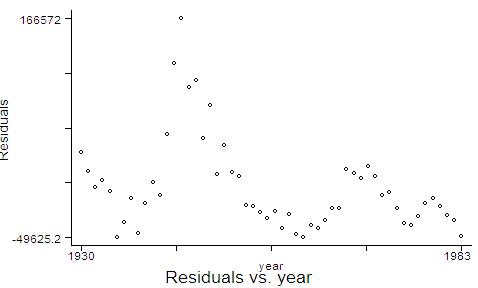
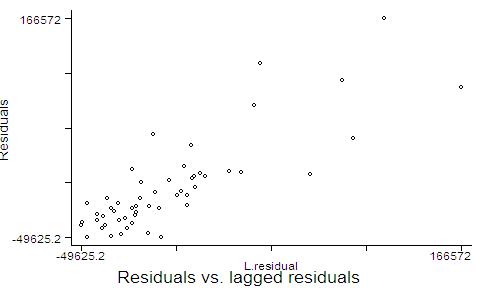
Obtain the residuals. residual<-resid(Engle) Plot the residuals along time. ts.plot(year,residual, gpars=list(main="Chickens vs. eggs: Is there cointegration?", xlab="year", ylab="residuals")) Plot also the residuals versus lagged residuals. Draw your conclusions (iii) Test whether the residuals are I(0). (See discussion below in the respective STATA section). At the end of the test,
please provide a table summarizing your results. Comment your findings.
Engle-Granger in Stata: Follow the same 3 steps as above, with small software adjustments: (i) Pre-test the variables for the presence of unit roots and check if they are integrated of the same order (ii)Regress chickens against eggs (long run equilibrium relationship) regress chic egg
Source | SS
df MS
Number of obs = 54
------------------------------------------------------------------------------
Obtain the residuals from
this equation
Graph the residuals against
time
Graph the residuals against
lagged residuals.
Draw your comments. (iii) Proceed with a unit root test on the residuals, as you have done the ADF test for unit roots on chickens and eggs. Consider lags 0 to 4, though. This is a residual-based version of the ADF test. The only difference from the traditional ADF to (this version of) the Engle-Granger test are the critical values. The critical values to be used here are no longer the same provided by Dickey-Fuller, but instead provided by Engle and Yoo (1987) and others (see approximated critical values in Table B.9, Hamilton 1994). This happens because the residuals above are not the actual error terms, but estimated values from the long run equilibrium equation of chickens against eggs. Some authors (e.g., Enders,
1995) consider a fourth step, consisting in the estimation of error-correction
models and checking of models adequacy. However, you are not requiredto
do that for the purposes of the problem set 3.
III. Cointegration: Johansen Test I recommend you to sketch the Johansen test, explaining the NULL and the ALTERNATIVE hypotheses. Then I suggest you to use the R code johansen.R, provided by Prof. Koenker, and available at http://www.econ.uiuc.edu/~econ472/routines.html: #Copy
from this point:
Your job is to copy the code above and paste in the R console. This will create a R function called "johansen" that calculates the eigenvalues. The command to obtain the eigenvalues is: johansen(cbind(egg,chic),
L=1)
The code above refers to
the case including trend and intercept, and the appropriate critical values
should be used. Note that the theoretical background here is essential,
given that you need to interpret the eigenvalues and calculate the test
statistic by yourself, before to draw your conclusions.
Johansen Test in Stata:
. tsset time . vecrank egg chic
You should note that the eigenvalues
are equal than before.
Could you interpret the results? What is your conclusion?
|
||||||