|
||||||
| Applied
Econometrics
Econ 508 - Fall 2008 e-Tutorial 2: A Brief Introduction to R |
||||||
| Welcome
to e-Tutorial, your on-line help to Econ508. The introductory material
presented below is the second of a series of handouts that will be
distributed along the course, designed to enhance your understanding of
the topics and your performance on the problem sets. The present issue
focuses on the basic operations of R. The core material was extracted from
Douglas Simpson's "Computational Statistics" (2001) course, and
Gregory Kordas' Econ472 (1999) class notes. The usual disclaimers
apply.
What's
R?
Accessing
R
Installing
R (Windows Version)
Useful Links
Downloading
Data
Example
- The U.S. Economy in the 1990s
To download
the data, please follow the general steps below:
US90<-read.csv("C:/Econ472/US90.csv",
header=T)
Save the file
as US90code.txt. This will create a routine to download the data.
Here you are naming the data set as "US90" and asking R to import it from
the file "US90.csv" located in the directory "C:/Econ508/". The term "header"
refers to the names of the variables in the first row. The lines 2-9 corresponds
to each individual variable - in order to work with them, you need to extract
them from the data frame (single object) and give respective names after
that (multiple objects).
f) Start R
(i.e., run RGui.exe). In the toolbar, go to "File", "Source R code", and
open the file US90code.txt containing your routine. (Be careful to
name the right directory where you have saved your routine.)
g) In the window called R Console, type US90. You will be able to see the matrix containing the data (a.k.a. data frame). If you type the name of a single variable, you will be able to visualize that on the screen as a vector. Now you are ready to work with your data!! Basic Operations
If you also
wish to know the standard deviation of the series, type
If you are
only interested in a single variable, just include its name after the command
If you are
in interested only in subset of your data, you can inspect it using filters.
For example, begin by checking the dimension of the data matrix:
This means
that your data matrix contains 11 rows (corresponding to the years 1992
to 2002) and 8 columns (corresponding to the variables). If you are only
interested in a subset of the time periods (e.g., the years of the Clinton
administration), you can select it as a new object:
and then compute
its main statistics:
If you are
only interested in a subset of the variables (e.g., consumption and investment
growth rates), you can select them by typing:
and then compute
its main statistics:
To create new variables, you can use traditional operators (+,-,*,/,^) and name new variables as follows: add or
subtract: lagyear<-year-1
Last, but
not least, the Help command (e.g., type help("log") in the R Console) contains
short but useful information on the main packages with functions provided
by R. Later in Econ508, you will learn how to create your own functions
in R.
Exploring Graphical Resources Suppose now
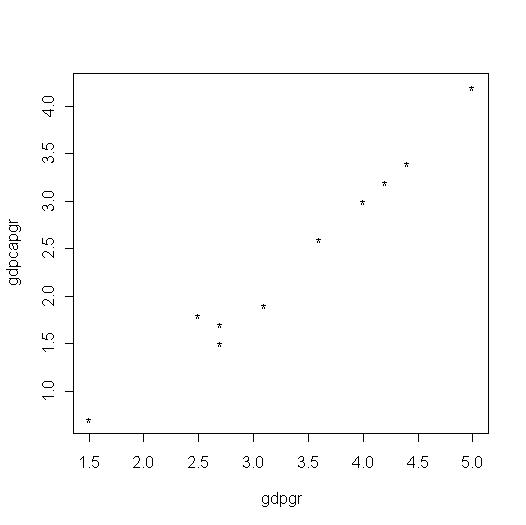
you want to check the relationship among variables. For example, suppose
you would like to see how much GDP growth is related with GDP per capita
growth. This corresponds to a single graph that could be obtained as follows:
And the result
will be:
Another useful
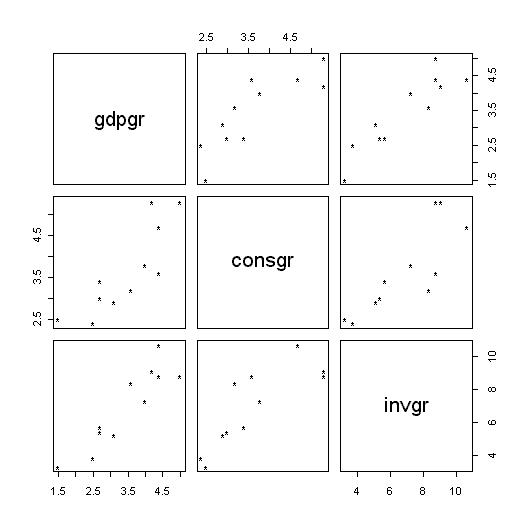
tool is the check on multiple graphs in a single window. For example, suppose
you would like to expand your selection, and check the pair wise
relationship of GDP, Consumption, and Investment Growth. You can obtain
that as follows:
The result will be:
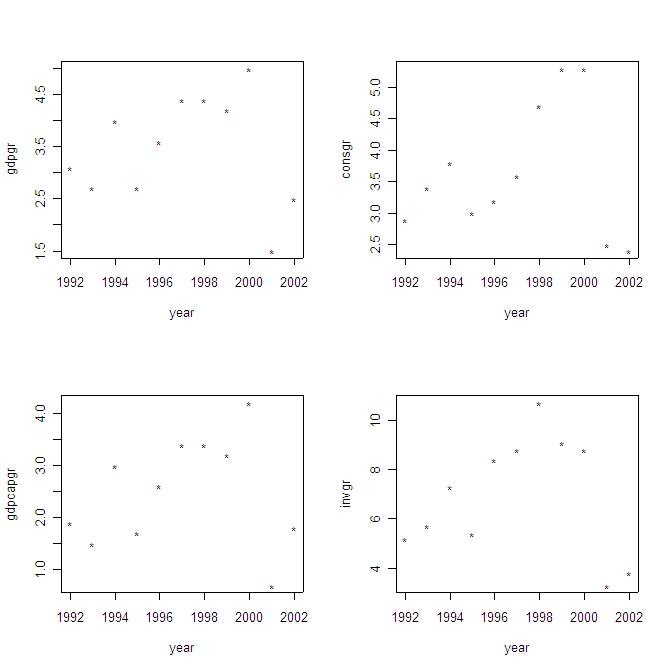
Suppose you would like to see the performance of multiple variables (e.g., GDP, GDP per capita, Consumption, and Investment growth rates) along time. The simplest way is as follows: par(mfrow=c(2,2))
Here the command "par(mfrow=c(2,2))" creates a matrix with 2 rows and 2 columns in which the individual graphs will be stored, while the command "plot" is in charge of producing individual graphs for each selected variable. The output will be:
You can easily
expand the list of variables to obtain a graphical assessment of the performance
of each of them along time. You can also use the graphs to assess cross-correlations
(in a pair wise sense) among variables.
Linear Regression Before running
a regression, it is recommended you check the cross-correlations among
covariates. You can do that graphically (see above) or using the following
simple command:
The output will be: > c1
From the matrix above you can see, for example, that GDP and GDP per capita growth rates are closely related, but each of them has a different degree of connection with unemployment rates (in fact, GDP per capita presents higher correlation with unemployment rates than total GDP). Inflation and unemployment present a reasonable degree of positive correlation (about 36%). Now you start
with simple linear regressions. For example, let's check the regression
of GDP versus investment growth rates. You just type:
And the output will be: Call:
Residuals:
Coefficients:
Residual
standard error: 0.4599 on 9 degrees of freedom
Please note that you don't need to include the intercept, because R automatically includes it. In the output above you have the main regression diagnostics (F-test, adjusted R-squared, t-statistics, sample size, etc.). The same rule apply to multiple linear regressions. For example, suppose you want to find the main sources of GDP growth. The command is: model2<-lm(gdpgr~consgr+invgr+producgr+unemp+inf)
And the output is: Call:
Residuals:
Coefficients:
Residual standard
error: 0.517 on 5 degrees of freedom
In the example above, despite we have a high adjusted R-squared, most of the covariates are not significant at 5% level (actually, only investment is significant in this context). There may be many problems in the regression above. During the Econ508 classes, you will learn how to solve those problems, and how to select the best specification for your model. You can also
run log-linear regressions. To do so, you type:
And the output will be: Call:
Residuals:
Coefficients:
Residual
standard error: 0.1729 on 5 degrees of freedom
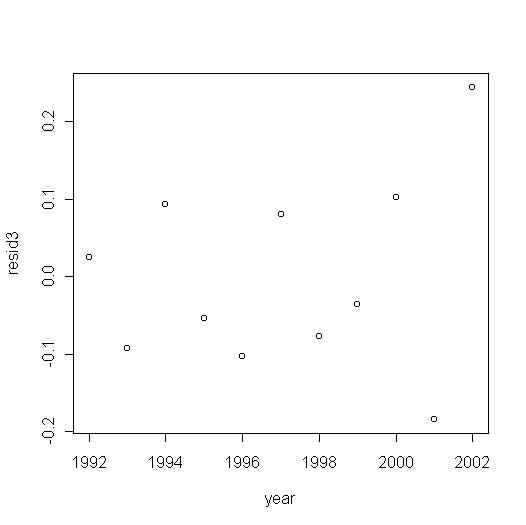
Finally, you
can plot the vector of residuals as follows:
The output will be:
You can also
obtain the fitted values and different plots as follows:
Linear Hypothesis Testing Suppose you
want to check whether the variables investment, consumption, and productivity
growth matter to GDP growth. In this context, you want to test if those
variables matter simultaneously. The best way to check that in R is as
follows. First, run a unrestricted model with all variables:
Then run a
restricted model, discarding the variables under test:
Now you will
run a F-test comparing the unrestricted to the restricted model. To do
that, you will need to write the F-test function in R, as follows:
(The theory comes from Johston and DiNardo (1997), p. 95, while the R code
is a version of Greg Kordas' S code. I've adjusted it for this specific
problem.)
F.test<-function(u,r)
After that,
you can run the test and obtain the F-statistic and p-value:
$Fprob
And the conclusion
is that you can reject the null hypothesis of joint non-significance at
1.13% level.
Saving Operations in R The simplest
way to save commands in R is through the use of a routine. For example,
you can append your original routine US90code.txt with the commands you
have typed in the R console during the last session. Next time you open
this routine, all operations will be registered, and you can access previous
outputs by calling the objects you've created.
|
||||||