|
||||||
| Applied
Econometrics
Econ 508 - Fall 2007 e-Tutorial 19: Duration Models |
||||||
| Welcome.
This time we focus on Duration Models (a.k.a. Survival Analysis) in the
context of the problem set 5.
Downloading your data: You can download your data from the Econ 508 website (here) and save the file in your preferred directory (I'll save mine as "C:\weco.dat"). Then you open STATA and type: infile y sex dex lex kwit tenure censored using "C:\weco.dat" Drop the first line of the data set containing missing values (due to the labels of variables). Next you generate the variable lex squared: gen lex2=lex^2 Then save the file in STATA format (I'll save mine as "C:\weco.dta"). For the purpose of
this tutorial, I will use a subsample of the PS5 data set (by dropping
lex==12), to demonstrate the main techniques required in the problem set.
My results may differ from the original data set.
Question 5: In STATA, the first thing you need to do is to declare your data set as a survival-time data. You need to identify the "analysis time" variable, and the "failure" variable. The former indicates the duration of the process, while the latter indicates whether the data is censored. In the PS5 data set, "tenure" represents the "analysis-time" variable, i.e., the duration of the process, while "censored" represents the "failure" variable, assuming values of 0 if it is censored, and 1 if it is failure. stset tenure, failure(censored)
failure event: censored ~= 0 & censored ~= .
------------------------------------------------------------------------------
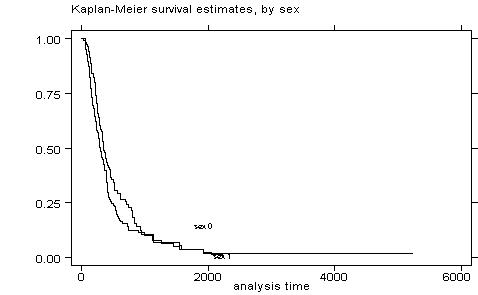
Part (a) Initially you need to generate the Kaplan-Meier estimator for men and women: sts graph, by(sex)
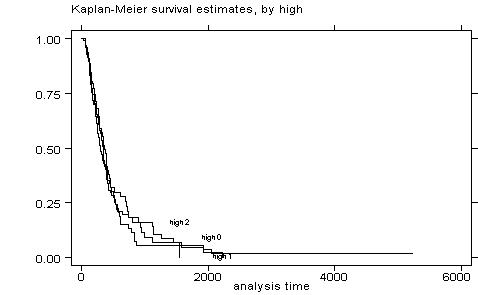
Then you need to stratify the sample into three categories of schooling. In my example I will use lex=13 as the benchmark, but you should adjust for lex=12 as requested by PS5: gen
high=0
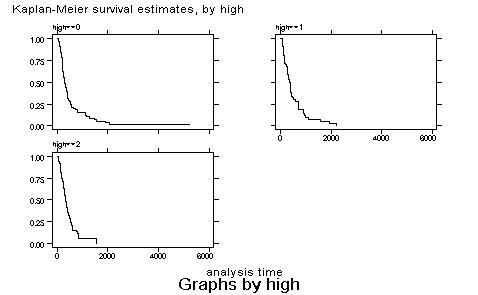
Sometimes the graph is too confused, and it is better to generate separated graphs: sts graph, by (high) separate
You can also test the equality of survivors as follows: sts test sex
failure _d: censored
Log-rank
test for equality of survivor functions
| Events
chi2(1) = 3.36
sts test high
failure _d: censored
Log-rank
test for equality of survivor functions
| Events
chi2(2) = 0.66
Part (b) Finally you need to estimate a Cox proportional hazard model, and compare with your results from question 3. You can obtain the Cox PH model as follows: stcox sex dex lex lex2 failure
_d: censored
Iteration
0: log likelihood = -977.68046
Cox regression -- Breslow method for ties No.
of subjects = 257
Number of obs = 257
------------------------------------------------------------------------------
In the output above, a hazard ratio equals one is the benchmark: if the hazard ratio is higher than one, the variable affects positively the hazard; if the hazard ratio is less than one, the variable contributes negatively to the hazard. This can be checked by asking for the coefficients rather than the proportional hazard rates representation of the Cox model: stcox sex dex lex lex2, nohr
failure _d: censored
Iteration
0: log likelihood = -977.68046
Cox regression -- Breslow method for ties No.
of subjects = 257
Number of obs = 257
------------------------------------------------------------------------------
| ||||||